

















2021年11月01日
自然言語処理技術のブレイクスルー
~文脈を理解するAI~
はじめに
近年DX(デジタルトランスフォーメーション)への注目が集まっており、社会の様々な場面で人工知能(AI)が活用されています。画像認識による検品の自動化や時系列データを活用した将来の需要予測など、AIは様々なシーンで活用されています。その中でも特に自然言語処理技術の発展に注目が集まっています。
自然言語とは、日本語、英語などの「人間が話す言語」です。そして自然言語処理とは、自然言語がもつ意味をコンピュータで解析する一連の処理のことを指し、文の分類、翻訳、検索、要約などを行うことができます。この自然言語処理の分野で大きなブレイクスルーとなったのが2018年にGoogleが発表した「BERT」です。今回はこのBERTをテーマに自然言語処理技術の発展についてご紹介します。
BERTとは
「人間が経験を通じて自然に学習する」のと同じように、「コンピュータ(AI)にデータから学習させる」仕組みを機械学習といい、その中でも人間の脳神経の仕組みを模倣したアルゴリズムのことを深層学習※1といいます。今回のテーマであるBERT(Bidirectional Encoder Representations from Transformers)は、深層学習を利用した自然言語処理に特化したモデル※2です。BERTの特徴としては大きく2点挙げられます。
BERTの特徴の1点目は、「文章の文脈を理解できる」ことです。この文脈の理解を実現するために、MLM(Masked Language Modeling)とNSP(Next Sentence Prediction)という2つの課題を与えて大量の文書データを学習させます。
1.MLM(Masked Language Modeling)とは
この課題では、BERTに「一部の単語を[MASK]という別の単語で置き換えた文」を入力します。BERTは入力文の単語の順番から文脈を考慮することで、[MASK]で置き換えられる前の単語を予測します。例えば、「私の好きなスポーツは野球で、いつか本場のアメリカで観戦してみたい。」の「野球」の部分が[MASK]に置き換えられた入力文をBERTに入力した場合、前後の「スポーツ」、「アメリカ」、「観戦」などの単語の並びから、[MASK]で置き換えられた単語が「野球」であることを予測します。BERTはうまく予測できるように学習を行うことで、単語に対応する文脈情報を獲得できます。
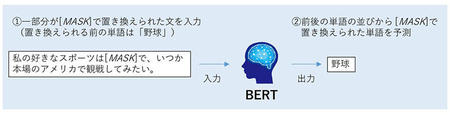 図1:MLM(Masked Language Modeling)の例
図1:MLM(Masked Language Modeling)の例
(クリックして拡大できます)
2.NSP(Next Sentence Prediction)とは
この課題では、BERTに「意味的につながりがある2文」、または「意味的につながりのない2文」を入力します。BERTは、2文の関係性を考慮することで「入力された2文に意味的につながりがあるかどうか」を予測します。
例①:意味的につながりがある2文
1:私は[MASK]とアメリカに行った。
2:そこで[MASK]に英語で話しかけられた。
例②:意味的につながりのない2文
1:私は[MASK]とアメリカに行った。
2:イルカは[MASK]の哺乳類だ。
それぞれの例をBERTに入力すると、BERTは入力された2文は意味的につながりがあるか、あるいはつながりがないかを予測します。BERTはうまく予測できるように学習を行うことで、単語の関係性だけでなく文章の関係性の情報も獲得できます。このように、2つの事前学習課題をうまく解けるように学習することで、BERTは文脈を理解できるようになります。
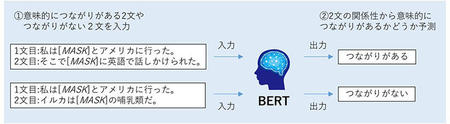 図2:NSP(Next Sentence Prediction)の例
図2:NSP(Next Sentence Prediction)の例
(クリックして拡大できます)
BERTの特徴の2点目は、大量の文書データを利用して事前学習を行ったBERTは自然言語の文章の特性をうまく学習できているため、解きたい課題に合った少量のデータを追加で学習させるだけで文書分類、検索、質疑応答、翻訳、要約など様々な自然言語処理の課題に応用することが可能であることです。このような性質を持つ言語モデルのことを汎用言語モデルといいます。BERT以前の言語モデルは、解決したい課題に合った大量のデータを学習させることが必要な課題特化型がほとんどであったため、たった1つのモデルに少量のデータを追加学習させるだけで様々な課題を解決できるBERTは画期的だとして注目を集めました。
※1深層学習:「大量のデータから自動で規則性や関連性を見つけ出し、判断や予測を行う」機械学習の1手法で、ディープラーニングとも呼ばれる。従来の機械学習では、データの中のどの部分に注目するか(特徴量)を人間が定めていたが、深層学習ではコンピュータが自動で特徴量を決定する。
※2モデル:機械学習の頭脳にあたるもの。データを入力すると、何かしらの評価や判断を行い、出力値を出すことができる。
BERTができること
BERTが「文脈を理解できる」ということを示すために、「2文の類似度を計算する課題」を考えてみましょう。図3のように、質問として企業の「アップル」が含まれる文、文書①として果物の「アップル」が含まれる文、文書②として企業の「Apple」が含まれる文があるとします。
BERT以前の言語モデルでは単語の出現頻度を利用して2文の類似度を計算します。この方法では、2文に表記が同じ単語があると類似度が高くなるため、質問と同じカタカナ表記の「アップル」という単語を含む文書①の方が、文の意味は似ていないのに類似度が高くなってしまう問題がありました。
一方、BERTを活用した類似度の計算では、事前学習により文脈の情報を学習しているため、質問の「アップル」は企業、文書①の「アップル」は果物、文書②の「Apple」は企業名だと文脈から意味を考慮して類似度を算出します。したがって、文意が似ている文書②の方が質問との類似度が高くなります。つまり、BERTを活用することで文脈を考慮した人間の感覚に近い結果を得ることができるようになっています。
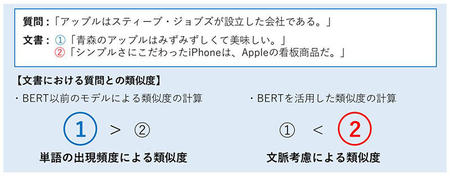 図3:BERTを活用した2文の類似度の計算
図3:BERTを活用した2文の類似度の計算
(クリックして拡大できます)
自然言語処理技術の現状と今後
自然言語処理技術は、BERT以後様々なBERTの派生形モデルが研究されたり、本コラムの2021年5月の記事で紹介しているGPT-3※3などBERT以外の汎用言語モデルが登場したりするなど、ここ数年で発展が著しい分野です。
日本でも、リクルート、バンダイナムコ研究所、rinna等の企業が、大量の日本語の文書データを事前学習させたBERTやその派生型、その他の汎用言語モデルの事前学習モデルを開発し公開しています。また、LINEは2020年にBERTとは別の新たな日本語に特化した大規模汎用言語モデルの開発を発表しました。このように、日本企業も自然言語処理分野の研究開発に取り組んでおり、こうした企業が公開している事前学習モデルを活用することで、比較的簡単に最新の自然言語処理技術を活用して課題を解決できるようになってきています。
日進月歩の自然言語処理技術から今後も目が離せません。
※3:人工知能(AI)による次世代のテキスト生成
https://www.kobelcosys.co.jp/column/itwords/20210501/
2021年11月
最新の記事
年別
ITの可能性が満載のメルマガを、お客様への想いと共にお届けします!
Kobelco Systems Letter を購読




