















2023年05月01日
データドリブン経営を促進するデータファブリック
はじめに
現代の企業において「データ」は重要な資産として扱われています。膨大の量のデータ、いわば「ビッグデータ」の波が押し寄せる中で、組織内に蓄えられたデータは大きな潜在価値を生み出す可能性があります。データの可視化やAIの開発により、データから新しい価値を引き出すことを「データアナリティクス(データ分析)」と呼んでいます。データを収集・変換・分析し、価値を作るプロセスを表す言葉です。そして、その分析結果をもとに企業の意思決定や課題解決に取り組む「データドリブン経営」はDX推進において有効な施策ともいわれています。近年の技術の発展に伴い、データの発生元は日々増加しています。さらに、データを求めるユーザー数は増え、種類も多様化しています。
データウェアハウスからデータレイクへ
従来、大量のデータを扱う場合は、「データウェアハウス」という基盤を利用してきました。データウェアハウスは、データ利用の目的に応じた変換作業を経て、「整理」して保存する場所です。料理に例えると、焼き魚用に魚を切り身にして、すぐ使える状態に魚を「整理」し、保存するという意味になります。
 図1:データウェアハウスのイメージ
図1:データウェアハウスのイメージ
(クリックして拡大できます)
しかし、近年ではデータを活用する目的は多様化しており、特定の目的のために「整理」し、保存する方式では全てのニーズに対応することは難しくなっています。そのため、データの保存場所として「データレイク」が使われるようになりました。データレイクは「整理」されていない、「生」のデータも保存出来る「湖(保管場所)」です。保存したあと、必要なデータを必要な時に取り出して目的に応じて活用することができます。
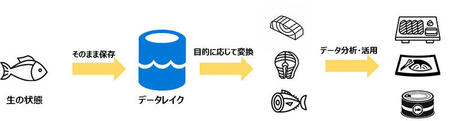 図2:データレイクのイメージ
図2:データレイクのイメージ
(クリックして拡大できます)
データレイクの登場により、保存された膨大なデータを利用したAI開発や可視化など、多くのデータ活用のニーズに応えることができるようになりました。現在は、データ規模やデータ活用要件に応じてデータウェアハウスとデータレイクを使い分ける企業が多くなっています。
データのサイロ化
データウェアハウスとデータレイクはそれぞれ、データ活用のために大きな役割を果たすアーキテクチャです。しかし、組織全体でデータ活用を促進する際、「データのサイロ化」という課題が生じることは少なくありません。 「データのサイロ化」とは、組織内部のデータが分散して保存され、有効活用ができていない状態を表します。例えば、企業内で他の部門、部署のデータを取り出すことができず、組織全体でのデータ活用が十分に活用できていないケースです。潜在価値があったとしても見逃してしまっては有効活用できず、ビッグデータの波の中で大きな損失に繋がってしまいます。

図3:データのサイロ化の説明資料
しかし、膨大なデータから必要なものだけを探すことは非常に難しいでしょう。また、散在する状況から収集する作業も手間がかかります。そのため、データの所在を「把握」し、適材適所かつ迅速に「供給」する仕組みが必要となります。
管理システムの登場、データファブリック(Data Fabric)
データファブリックとは、分散されたデータを効率的に管理、活用するためのアーキテクチャを表します。つまり、サイロ化されてしまったデータを含め組織全体で収集されたデータを把握し、潜在価値のあるデータを漏れなく活用するための管理システムです。データファブリックはデータウェアハウスとデータレイクを活用し、包括的にデータを管理します。つまり、これら二つの置き換えになるテクノロジーではありません。データファブリックとは広い概念であり、テクノロジーそのものよりはガバナンスに近い「管理」の概念になります。
例えば、料理で「ピリ辛きゅうり」を作ると仮定しましょう。唐辛子ときゅうり、ごま油が必要です。それぞれの材料は分散されたところに保存されている場合、これらを1つずつ取り出す必要があります。しかし、図4のようなデータへのアクセスが整理されていない場合どうなるでしょうか。
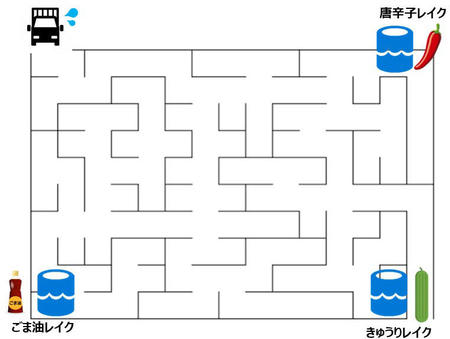 図4:サイロ化されたデータレイク
図4:サイロ化されたデータレイク
(クリックして拡大できます)
必要とされるデータにたどり着くことが難しく、時間もコストも浪費されてしまいます。そのため、どのデータがどこにあるのか把握し、いつでも取り出せるようにする取り組みが必要です。その際に、利用されるのがデータを「リスト化」し、カタログのように検索を可能とする「データカタログ」と、分散されたデータの保存場所を繋ぐ通り道を構築する「データパイプライン」です。
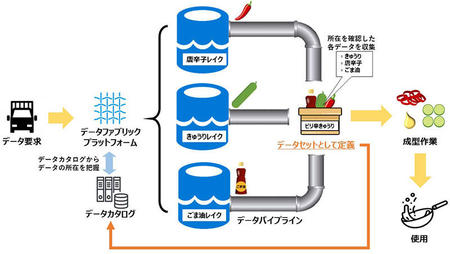 図5:データファブリックの例
図5:データファブリックの例
(クリックして拡大できます)
データパイプラインからデータを迅速に取り出すことができるうえ、取り出したデータリストをカタログ化することで今後の取り出し速度を向上させることができます。例えば、図5で利用された材料は「ピリ辛きゅうり」データセットとして定義され、今後ピリ辛きゅうりを作るたびに迅速に取り出せるようになります。このように、データ全体を把握・連携することで、データへのアクセスを柔軟にするデータ管理システムこそデータファブリックが目指す理想的な姿です。
データファブリックはデータドリブン経営のビジネス課題となるデータのサイロ化を防止し、各所に散在するデータの可視化と統合的なビューの提供を可能にします。さらに、組織全体のデータを把握することにより、組織をまたがるデータ活用を促進します。
データファブリックの事例
それではデータファブリックを導入し、分散された環境のデータを統合した事例をご紹介します。ある科学技術研究所では公共機関からデータを収集しており、データは様々な種類から構成されています。研究所は、膨大なデータの中から研究員が欲しいデータへ迅速にアクセスできる仕組みを必要としていました。そのため、複雑で多様なデータセットを処理できるデータファブリックを構築しました。
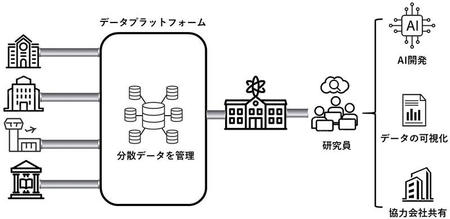 図6:データファブリック構築例
図6:データファブリック構築例
(クリックして拡大できます)
各公共機関から提供されるデータの管理を統合したことで、ニーズに応じて必要とされるデータに柔軟に接続できるようになりました。また、使用したデータセットを協力会社に公開したり、組織内で再利用したりといったことが可能になりました。このようにデータファブリックの導入により、迅速なデータ活用を実現し、研究員の生産性を飛躍的に向上させました。
まとめ
データウェアハウス、データレイクの登場により、データ活用は企業に大きな価値を与えました。しかし、データのサイロ化を中心とした課題は残されており、データファブリックのような分散データを管理する考え方が今後のデータ活用において重要な選択肢となることでしょう。
2023年5月
ITの可能性が満載のメルマガを、お客様への想いと共にお届けします!
Kobelco Systems Letter を購読




